
Proxmox monitoring
A toolset to gather temperature and power consumption metrics then collect in Prometheus. Can be found on GitHub https://github.com/jaroslawhartman/proxmox-monitoring/tree/main
Architecture
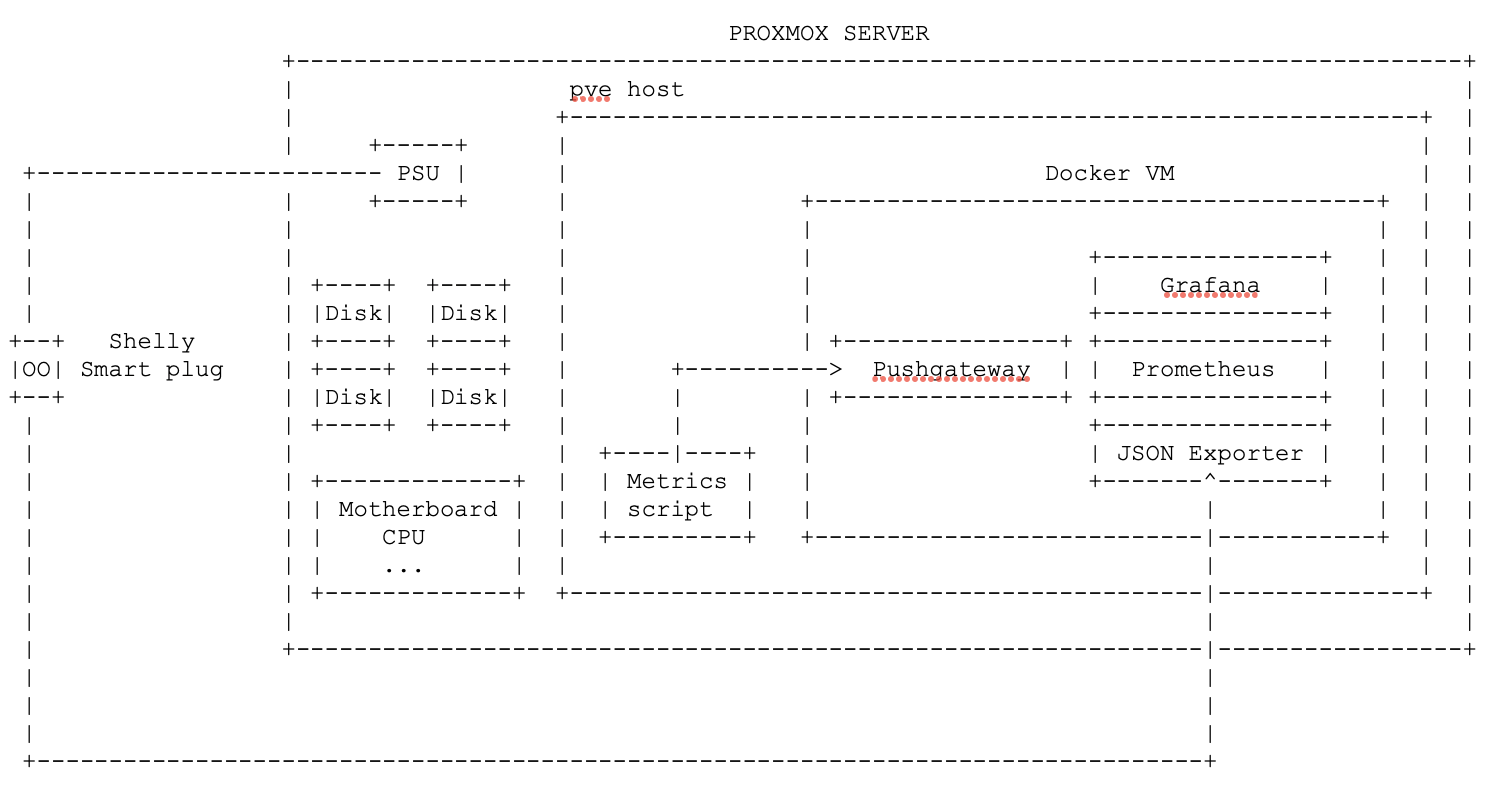
Components
- Proxmox Server 8.1.3
Host
Collecting script is running every minute on the pve host
* * * * * 